前回からはじめた自作の言語処理系開発日記の第1回目です。今回から実際のコードを書いていきたいと思います。
前回の記事でも紹介したとおり、全体の構成は以下のような感じです。
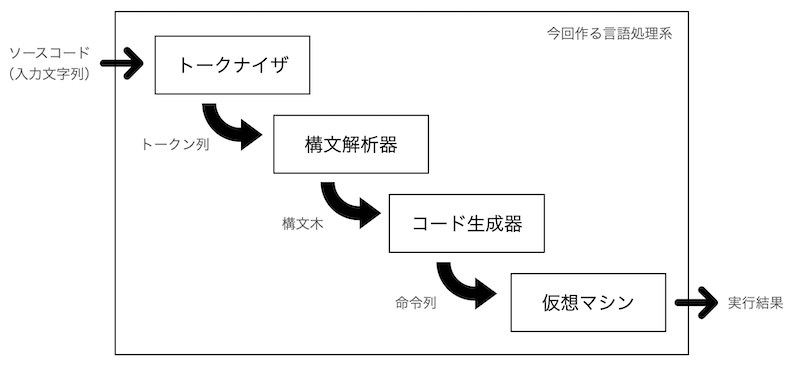
今回は、それぞれの仕組みの骨格と簡単な機能の実装を進めていくことにします。
今回の目標
はじめの1歩として実装するのは、数値の読み込みです。1つの数字を読み込んでそれを実行結果とするだけの機能を実装します。機能としてはシンプルですが、中身自体はしっかりトークナイズ→構文解析→命令生成→実行の流れを踏みます。
ちなみにですが、リポジトリ名は「rook」としました。私のGitHubのアイコンにもしている愛犬の名前です笑
実装してみる
トークナイザ
まずは入力文字列をトークンに分解するトークナイザです。最初にトークンを以下のような構造体で定義します。
// トークン関連の定義
typedef enum {
TK_NUM, // 数値
TK_EOF, // 終端
} TokenKind;
typedef struct {
TokenKind kind; // トークン種別
char *str; // トークン文字列
int len; // トークン長
} Token;トークンはその意味や役割に応じて種類が分かれるので、トークン種別(kind)を持たせます。現時点では数値の入力しか考えないので「数値トークン」のみです。strは入力文字列に対するトークンの開始位置、lenはその長さです。
トークナイズ本体の処理は以下のような感じです。欲しいのはトークン列なので、Tokenのvectorとして結果を返します(とはいえ、いまは1つのトークンだけ)。ここでも現時点では数値だけを読み取れれば良いので、数字以外はすべてエラー扱いです。
vector<Token> Tokenizer::tokenize(char* input)
{
vector<Token> tokens;
while(*input){
if(isdigit(*input)){
Token token = { TK_NUM, input, 0 };
for(; isdigit(*input); input++) token.len++;
tokens.push_back(token);
}
else{
cerr << "Invalid character : " << *input << endl;
exit(1);
}
}
tokens.push_back( Token{ TK_EOF, NULL, 0 } );
return tokens;
};構文解析器
続いて構文解析器です。ここでは実装の前に、この言語処理系の構文を決めます。構文定義にはBNF記法というものが使われますが、厳密な書き方は特に気にしません。実装に落とし込める形であれば何でもOKとします。
今回は「1つの数字を読み込む」だけなので、現時点での構文は「数値1つだけ」となります。これを表現してみるとこんな感じになります。
programは入力ソースそのもの、numは数値を表します。つまり「入力ソースは数値である」となります。このようなものを生成規則と呼んだりするそうです。
実装ですが、まずは構文解析の結果を表現するためのノードを定義します。
// ノード関連の定義
typedef enum {
ND_NUM, // 数値
} NodeKind;
typedef struct Node Node;
struct Node {
NodeKind kind; // トークン種別
Node *left; // 左辺
Node *right; // 右辺
int val; // ND_NUMのときに使う
};ここでもノードの種類を定義していますが、現時点では数値だけです。木構造を表現するために、左木(left)と右木(right)を持たせます。また、数値も1つのノードとして扱う必要があるので、その値(val)も用意します。
続いて構文解析の処理ですが、ここではさきほど定義した構文に対応させる形で実装します。そのため、numというメソッドを実装し、それをprogramというメソッド内で呼び出すようにします。構文が複雑になってきても、この方法であれば比較的素直に実装に落とし込むことができ、再帰的に処理しやすくなるというメリットがあります。
Node* Parser::program(void)
{
return num();
};
Node* Parser::num(void)
{
Node* node = new Node();
node->kind = ND_NUM;
node->val = atoi(token->str);
token++;
return node;
};
Node* Parser::parse(vector<Token>& tokens)
{
token = tokens.begin();
return program();
};コード生成器
お次はコード生成器です。ここでは、入力として構文解析の結果(Nodeの木)を受け取って実際の命令に変換します。
今回は「数値を受け取ってそれを実行結果とする」という処理が実現できればOKですが、作成する処理系は「実行結果=スタック」のトップなので、「数値をスタックに積む」という命令1つで事足ります。
まず、命令については以下のような構造体で表現します。本来の命令はバイナリ列ですが、ここでは簡単のためにこうしました。
// 命令関連の定義
typedef enum {
OP_PUSH, // Push
} OP_CODE;
typedef struct {
BYTE opcode; // オペコード
DWORD operand; // オペランド
} Operation;命令の種類はPUSHだけ、命令の中身もオペコード+オペランドだけです。これを使ってコード生成の処理を書くとこんな感じになります。最終的な出力は命令列(Operationのvector)です。
vector<Operation> Generator::codegen(Node* node)
{
switch(node->kind){
case ND_NUM:
operations.push_back( Operation{ OP_PUSH, node->val } );
break;
default:
break;
}
return operations;
};ここでも、現時点では数値1つ(ノードが1つだけ)しか入ってこない想定なので、左右の木の存在は気にしていません。
仮想マシン(実行系)
最後に仮想マシンです。今回はスタックマシンとして実装するので、内部的にスタック用のメモリと、スタックトップを示すポインタ1つを用意しておきます。
DWORD stack[STACK_SIZE]; // スタック
DWORD *sp; // スタックポインタあとは、入力された命令列を読みながら、各命令に対応した処理を行うだけです。
DWORD VM::run(vector<Operation>& code)
{
vector<Operation>::iterator op = code.begin();
while(op != code.end()){
switch(op->opcode){
case OP_PUSH:
{
push(op->operand);
break;
}
default:
break;
}
op++;
}
// スタックトップの値を実行結果とする
return pop();
};一応、これで数値を読み込んでそれを実行結果とする処理系が実装できました。現時点では言語処理系と言い張るのは無理がありますが、ここから少しづつ育てていきたいと思います。
実装コード全体
今回の実装のコミットは以下のハッシュになります。全体はそちらをご覧くださいm(_ _)m
ではでは