今回から連載企画として、自作の言語処理系の開発日記を書いていこうと思います。
以前、プログラミング言語もどきとして「particle」というものを作ったのですが、進めていく内に手詰まりになって頓挫してしまいました。
しかし、最近「低レイヤを知りたい人のためのCコンパイラ作成入門」というオンラインブックを見て「作りたい欲」が高まってきたので、あらためて挑戦してみることにしました。
開発過程のコードはGithubでオープンにしていくつもりです。モチベーション維持のためにも、その詳細をこのブログで紹介しながら進められればと思います。
全体の構成案
過去に作った「particle」はスクリプト言語のように、ユーザーからの入力を逐一解析して処理する仕組みでした。しかし、今回はコンパイラ型言語のように、ソースコードから独自の命令列を吐き、それを独自の実行系で動かすという形にしたいと思います。
全体のイメージはこんな感じです。大きく分けて4つの仕組みを作る必要があります。
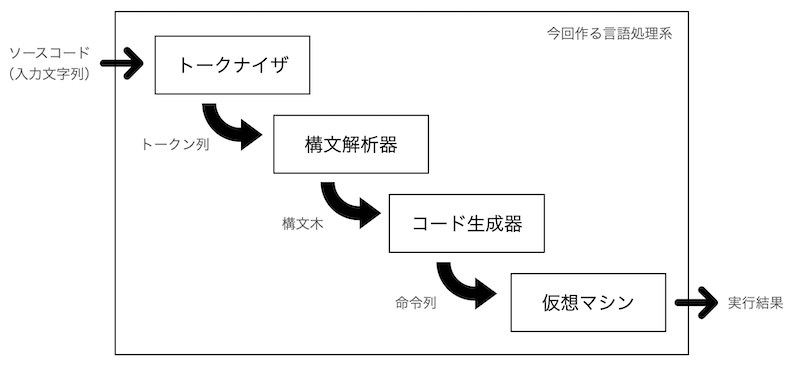
トークナイザ
入力文字列をトークンという意味を持った記号に分解する仕組みです。例えば「num = 1 + 3」という文字列が入力された場合、それをトークンに分解した結果は以下のようになります。
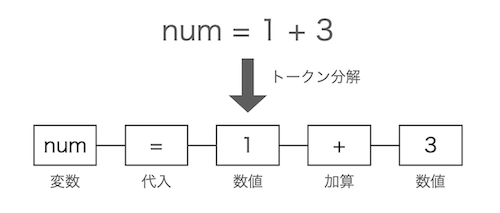
入力文字列を部品に分けて、それらに意味づけをしていくイメージです。トークナイザの入力は文字列、出力はトークン列となります。
構文解析器
トークナイザで生成されたトークン列を、その言語の文法に従って解析し構造化する仕組みです。一般的に、解析結果は木構造で表現されます。先で例に挙げたトークン列を構造化すると以下のようになります。

このように、代入や加算を木構造で表現することで、式全体を1つのノードを頂点とする構文木で表すことができます。構文解析器の入力はトークン列、出力は構文木になります。
コード生成器
構文解析器で生成した構文木を辿りながら、実行系が処理するための命令列を吐き出す仕組みです。左優先で木を辿りながら、各ノードに対応する命令列を吐き出すのが一般的(?)かと思います。
各命令は基本的にはオペコード+オペランドの組み合わせで定義されます。オペコードで処理の内容、オペランドで処理対象のデータを指定します。
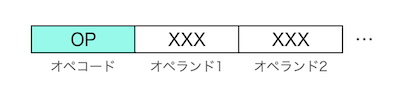
今回は実行系も自作なので、それに合わせた命令セットも自分で決めちゃえばOKです。
仮想マシン
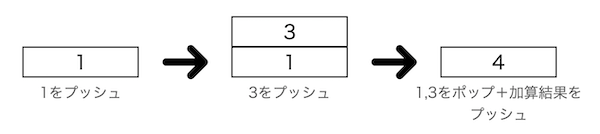
コード生成器が吐いた命令列を処理する実行系です。カッコよく「仮想マシン」と呼びますが大層なことはせず、シンプルにスタックマシンとして実装することにします。スタックマシンとは、スタックに対するデータの出し入れによって計算を行う仕組みです。例えば「1+3」という計算を行うときには、
- 数値の1をスタックに積む
- 数値の3をスタックに積む
- スタックから数値を2つ取り出して、その加算結果をスタックに積む
という流れを踏みます。図で表すとこんな感じです。この場合「最終的にスタックの一番上に積まれている値=式の計算結果」となります。
進め方と環境
今回の開発については、
- 最初から性能面や設計のキレイさはあまり考えない
- 1つ1つ機能を追加する形でつくる
という方針で進めます。あくまでも趣味の個人開発なので「間違っていてもOK」がモットーです。最初から正しい姿を求めてしまうと疲れてしまうので、トライ&エラーでコツコツと育てていこうと思います。
開発環境はLinux、言語はC++です。こちらも特に意味はなく、単純にC++を使って何かを作ってみたかったという理由だけです。
ということで、次回から実際のコードを書きつつブログも更新していこうと思います。コードや記事の中身は私のような素人が書く内容なので、実際の言語処理系で使われる用語や設計とは異なっている可能性が大です。その点、ご容赦いただき期待せずお待ちください m(_ _)m
ではではノシ