プログラム中でバイナリデータを扱うときには、そのエンディアンに注意しないといけない場合があります。
例えば、バイナリデータとして「データ長(先頭4バイト)+データ本体」というフォーマットのデータがあった場合、先頭から4バイトを読み出してlong型にでもパースすればデータ長が分かると思うところですが、私はここでエンディアンの罠にはまりました。
エンディアンって?
そもそも、エンディアンって何?というお話ですが、エンディアンとは簡単に言えば「データの並び順」です。バイトオーダーとかバイト順とも言います。
例えば、long型の変数として2882400001 = 0xABCDEF01という数があった場合、変数の中身は4バイトありますが、その4バイトには以下の2通りの並び方が考えられます。
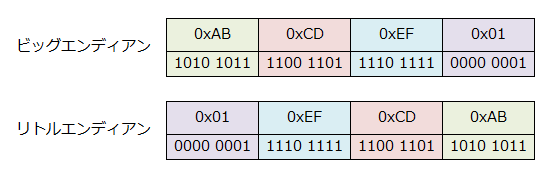
上の図のように、素直に先頭から後ろに向かって並べる形式をビッグエンディアン、逆に後ろから先頭に向かって並べる形式をリトルエンディアンと呼びます。変則的にミドルエンディアンという形式もあるそうですが、今回は置いておきます。
このように、変数をバイナリデータに変換するとエンディアンによってデータの並び方が変わるため、そのデータを扱うときにはどちらのエンディアンで並んでいるかを意識する必要があります。
さらに、エンディアンはCPUのアーキテクチャ依存なので、なおさらややこしいです(´・ω・)
実際に調べてみた
普段触っているCPUのエンディアンがどうなっているのか、以下のようなプログラムを書いて検証してみました。long型の変数をバイトデータとしてダンプしています。
#include <stdio.h>
int main(void) {
long num = 0xABCDEF01;
char* p = (char*)(&num);
int i;
printf("num = ");
for(i = 0; i < sizeof(long); i++) {
printf("0x%x ", p[i]);
}
printf("\n");
return 0;
}まずラズパイ2で実行してみたところ、以下のような結果になりました。ラズパイのCPU(ARM系)はリトルエンディアンのようです。
num = 0x1 0xef 0xcd 0xab
Windows10(Intel系)で実行してみても、先と同じ結果になりました。Intel系もリトルエンディアンのようですね。
調べてみたところ、ビッグエンディアンの代表格はPowerPC系で、リトルエンディアンだと思ったARM系は、正確にはどちらにもなれるバイエンディアンなのだそうです。奥深きCPUの世界を垣間見た気がしました。
エンディアンの変換関数
異なるアーキテクチャのCPUによるCPU間通信などを行う場合、両者で扱うデータをどちらかのエンディアンに合わせる必要がありますが、C言語にはちゃんとエンディアンの変換関数が用意されています。
以下がその関数です。ビット長とエンディアンの組み合わせで4つの関数があります。ホストバイトオーダーはホストマシンのエンディアン(CPU依存)、ネットワークバイトオーダーはビッグエンディアンのことを指します。
| 関数 | 説明 |
| uint32_t htonl(uint32_t hostlong) | 32bitのホストバイトオーダーをネットワークバイトオーダーに変換する |
| uint16_t htons(uint16_t hostshort) | 16bitのホストバイトオーダーをネットワークバイトオーダーに変換する |
| uint32_t ntohl(uint32_t netlong) | 32bitのネットワークバイトオーダーをホストバイトオーダーに変換する |
| uint16_t ntohs(uint16_t netshort) | 16bitのネットワークバイトオーダーをホストバイトオーダーに変換する |
あくまでも、ホストバイトオーダーとネットワークバイトオーダー間の変換関数なので、ホストがビッグエンディアンの場合はこれらの関数は何もしません。
まとめ
日頃、使っているCPUのエンディアンを意識することは少ないと思いますが、エンディアンの罠にはまらないためにも頭の片隅には止めておかないといけないなぁと感じました。特に組み込みの世界ではバイナリデータを扱うことが多く、1つの機器に複数のCPUが載っていることもしばしばありますし。
また余談ですが、CPU毎にエンディアンが分かれていった経緯なども調べてみると面白いかもしれませんね(・∀・)
ではではノシ